def_distance(p1:np.ndarray,p2:np.ndarray,mode:int=2)->float:'''
Get the distance between two points.
:param `p1`: the first point
:param `p2`: the second point
:param `mode`: which exponent to use when calculating distance,
using `2` by default for Euclidean distance
'''assertp1.shape==p2.shape,('_distance: dimensions not match for 'f'{p1.shape} and {p2.shape}')returnnp.linalg.norm(p1-p2,ord=mode)
def_get_k_nearest_neighbors(self,k:int,base_p:np.ndarray,dataset:int=Dataset.TRAIN_SET)->List[int]:'''
Get k nearest neighbors of a point from dataset. Each point (except the
base point) is denoted by its index in the dataset.
:param `base_p`: the base point
:param `dataset`: which dataset to use
'''ifdataset==Dataset.TRAIN_SET:data=self.train_dataelifdataset==Dataset.DEV_SET:data=self.dev_dataelse:data=self.test_data# Use a min heap of size k to get the k nearest neighborsheap:List[Tuple[float,np.ndarray]]=[]forp_iinrange(data.shape[0]):dist:float=_distance(base_p,data[p_i])if(len(heap)<k):heappush(heap,(-dist,p_i))else:heappushpop(heap,(-dist,p_i))# Return the indices of the k points in the datasetreturn[item[1]foriteminheap]
def_get_most_common_label(self,labels_i:List[int],dataset:int=Dataset.TRAIN_SET)->int:'''
Get the most common label in given labels. Each label is denoted by
its data point's index in the dataset.
:param `labels_i`: the indices of given labels
:param `dataset`: which dataset to use
'''ifdataset==Dataset.TRAIN_SET:all_labels=self.train_labelelse:all_labels=self.dev_labellabels:List[int]=[all_labels[i]foriinlabels_i]returnmax(set(labels),key=labels.count)
deffit(self,train_data:np.ndarray,train_label:np.ndarray)->None:'''
Train the model using a training set with labels.
:param `train_data`: training set
:param `train_label`: provided labels for data in training set
'''# Shuffle the dataset with labelsasserttrain_data.shape[0]==train_label.shape[0],('fit: data size not match for 'f'{train_data.shape[0]} and {train_label.shape[0]}')shuffled_i=np.random.permutation(train_data.shape[0])shuffled_data:np.ndarray=train_data[shuffled_i]shuffled_label:np.ndarray=train_label[shuffled_i]# Separate training set and development set (for validation)train_ratio:float=0.75train_size:int=floor(shuffled_data.shape[0]*train_ratio)self.train_data=shuffled_data[:train_size]self.train_label=shuffled_label[:train_size]self.dev_data=shuffled_data[train_size:]self.dev_label=shuffled_label[train_size:]print('=== Training ===')# Compare the predicted and expected results, calculate the accuracy# for each parameter k, and find out the best k for prediction.k_threshold:int=train_sizeiftrain_size<20else20accuracy_table:List[float]=[0.0]max_accuracy:float=0.0forkinrange(1,k_threshold):predicted_labels:List[int]=[]forpinself.dev_data:k_nearest_neighbors:List[int]=self._get_k_nearest_neighbors(k,p,Dataset.TRAIN_SET)predicted_label:int=self._get_most_common_label(k_nearest_neighbors,Dataset.TRAIN_SET)predicted_labels.append(predicted_label)prediction:np.ndarray=np.array(predicted_labels)accuracy:float=np.mean(np.equal(prediction,self.dev_label))accuracy_table.append(accuracy)print(f'k = {k}, train_acc = {accuracy*100} %')ifaccuracy>max_accuracy:max_accuracy,self.k=accuracy,kprint(f'best k = {self.k}\n')
defpredict(self,test_data:np.ndarray)->np.ndarray:'''
Predict the label of a point using our model.
:param `test_data`: testing set
'''self.test_data=test_dataprint('=== Predicting ===')predicted_labels:List[int]=[]forpinself.test_data:k_nearest_neighbors:List[int]=self._get_k_nearest_neighbors(self.k,p,Dataset.TRAIN_SET)predicted_label:int=self._get_most_common_label(k_nearest_neighbors,Dataset.TRAIN_SET)predicted_labels.append(predicted_label)prediction:np.ndarray=np.array(predicted_labels)returnprediction
defgenerate()->None:'''
Generate datasets using different parameters, and save to a file for
further use.
'''classParameter(NamedTuple):mean:Tuple[int,int]cov:List[List[float]]size:intlabel:intdef_generate_with_parameters(param:Parameter)->np.ndarray:'''
Generate a dataset using given parameters.
:param `param`: a tuple of `mean`, `cov`, `size`
`mean`: the mean of the dataset
`cov`: the coefficient of variation (COV) of the dataset
`size`: the number of points in the dataset
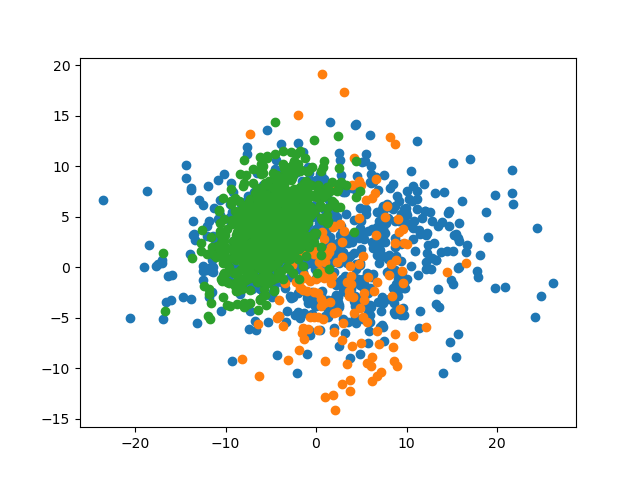
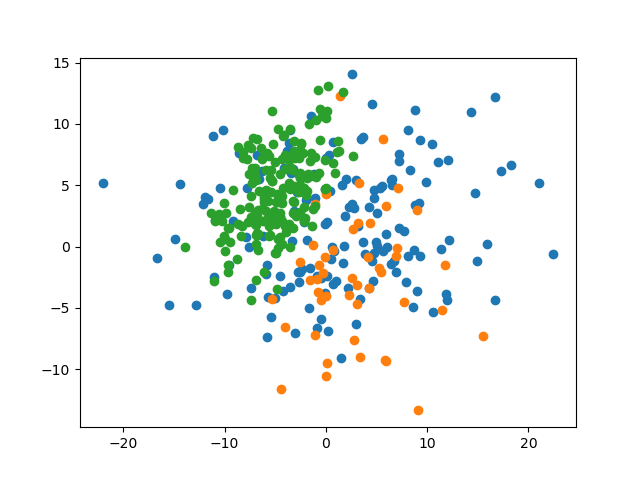
'''returnnp.random.multivariate_normal(param.mean,param.cov,param.size,)parameters:List[Parameter]=[Parameter(mean=(1,2),cov=[[73,0],[0,22]],size=800,label=0,),Parameter(mean=(16,-5),cov=[[21.2,0],[0,32.1]],size=200,label=1,),Parameter(mean=(10,22),cov=[[10,5],[5,10]],size=1000,label=2,),]data:List[np.ndarray]=[_generate_with_parameters(param)forparaminparameters]indices:np.ndarray=np.arange(2000)np.random.shuffle(indices)all_data:np.ndarray=np.concatenate(data)all_label=np.concatenate([np.ones(param.size,int)*param.labelforparaminparameters])shuffled_data:np.ndarray=all_data[indices]shuffled_label:np.ndarray=all_label[indices]train_data:np.ndarray=shuffled_data[:1600]train_label:np.ndarray=shuffled_label[:1600]test_data:np.ndarray=shuffled_data[1600:]test_label:np.ndarray=shuffled_label[1600:]np.save('data.npy',((train_data,train_label),(test_data,test_label),))
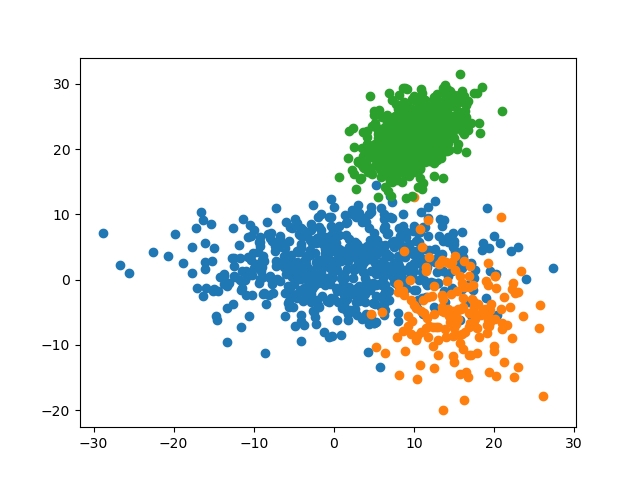
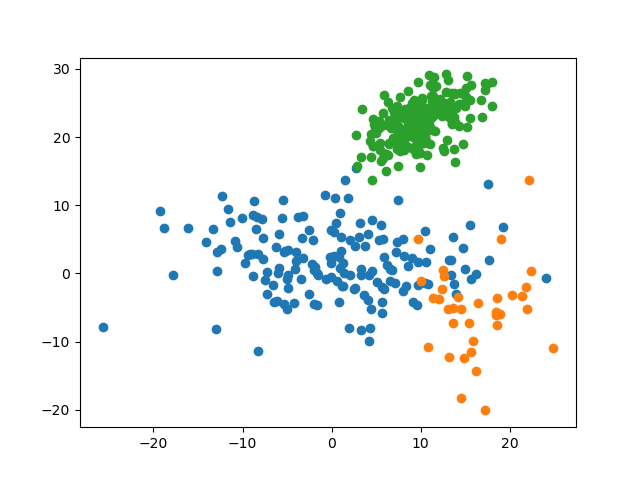
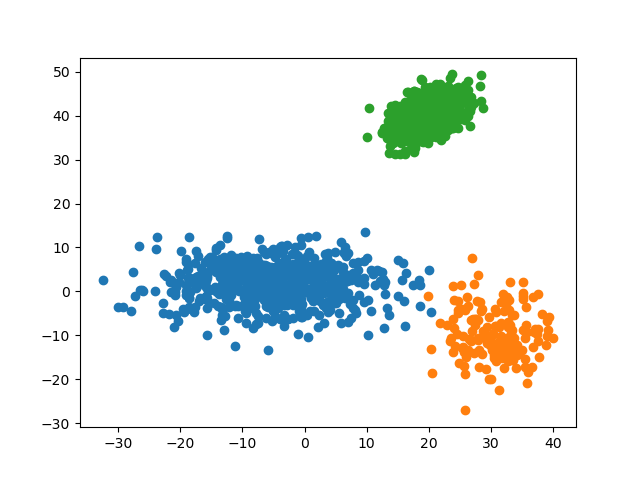
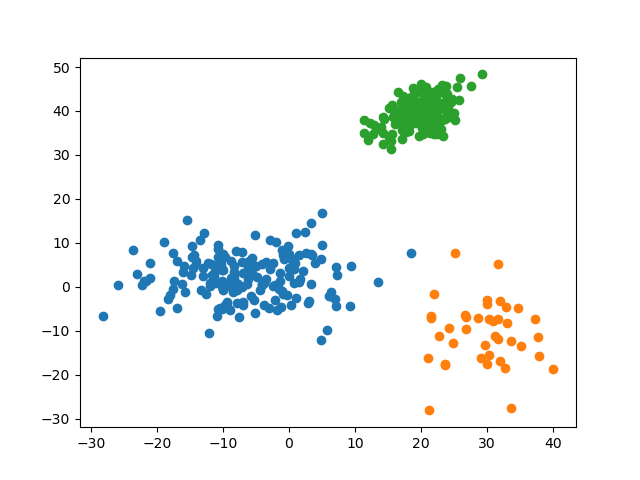
defdisplay(data:np.ndarray,label:np.ndarray,name:str)->None:'''
Visualize dataset with labels using `matplotlib.pyplot`.
:param `data`: dataset
:param `label`: labels for data in the dataset
:param `name`: file name when saving to file
'''datasets_with_label:List[List[np.ndarray]]=[[],[],[]]foriinrange(data.shape[0]):datasets_with_label[label[i]].append(data[i])fordataset_with_labelindatasets_with_label:dataset_with_label_:np.ndarray=np.array(dataset_with_label)plt.scatter(dataset_with_label_[:,0],dataset_with_label_[:,1])plt.savefig(f'img/{name}')plt.show()