
计组 - Lab 3: Cache
32 位 256 bytes 4 路组相联(参数可调节)高速缓存,使用 SystemVerilog 编写。
Introduction to Computer Systems II (H) @ Fudan University, spring 2020.
1 参数
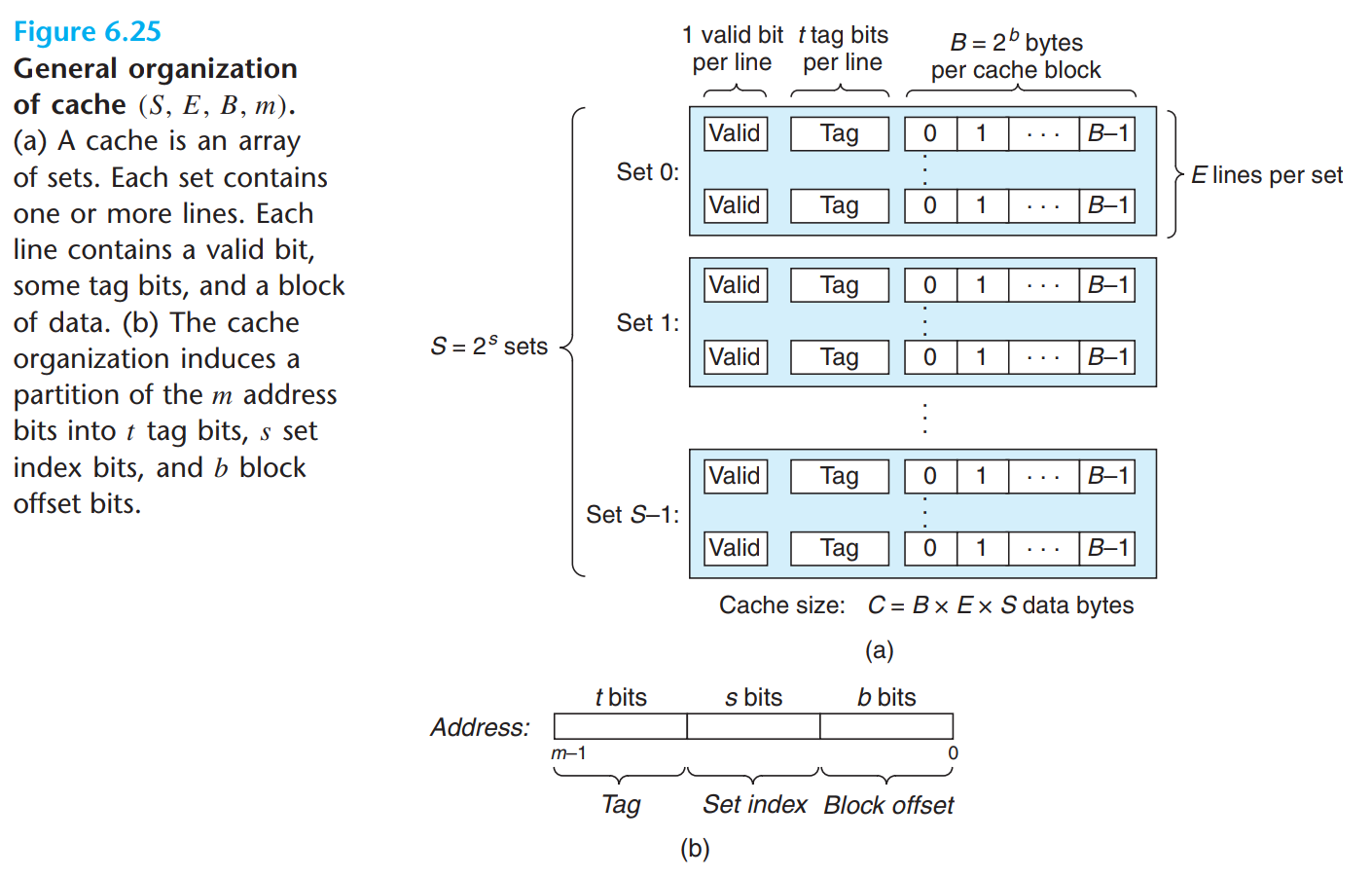
本缓存(Cache)在实现中默认使用 4 路组相联映射:总共 4 个 set,每个 set 中包含 4 个 line,每个 line 中存储 4 个 word。默认采用 LRU(Least Recently Used)替换策略,写内存时采用写回法(write-back)。
在 cache.svh 中可调整以下参数:
CACHE_T:地址中 tag 的位数 $t$,默认为 $26$CACHE_S:地址中 set index 的位数 $s$,对应组数为 $2^s$,默认为 $2$CACHE_B:地址中 block offset 的位数 $b$,对应行的大小为 $2^{b-2}$ 个 word(即 $2^b$ bytes),默认为 $4$CACHE_E:每组的行数 $e$,默认为 $4$
要求 $t+s+b=32$,即地址位数 $m$。通过调整参数 CACHE_E,即可实现 $e$ 路组相联映射。
在 replace_controller.svh 中可调整以下参数:
REPLACE_MODE:当前缓存替换策略 $\mathrm{mode}$,目前实现了以下策略:- LRU:Least Recently Used,对应 $\mathrm{mode}=0$
- RR:Random Replacement,对应 $\mathrm{mode}=1$
- LFU:Least Frequently Used,对应 $\mathrm{mode}=2$
2 结构
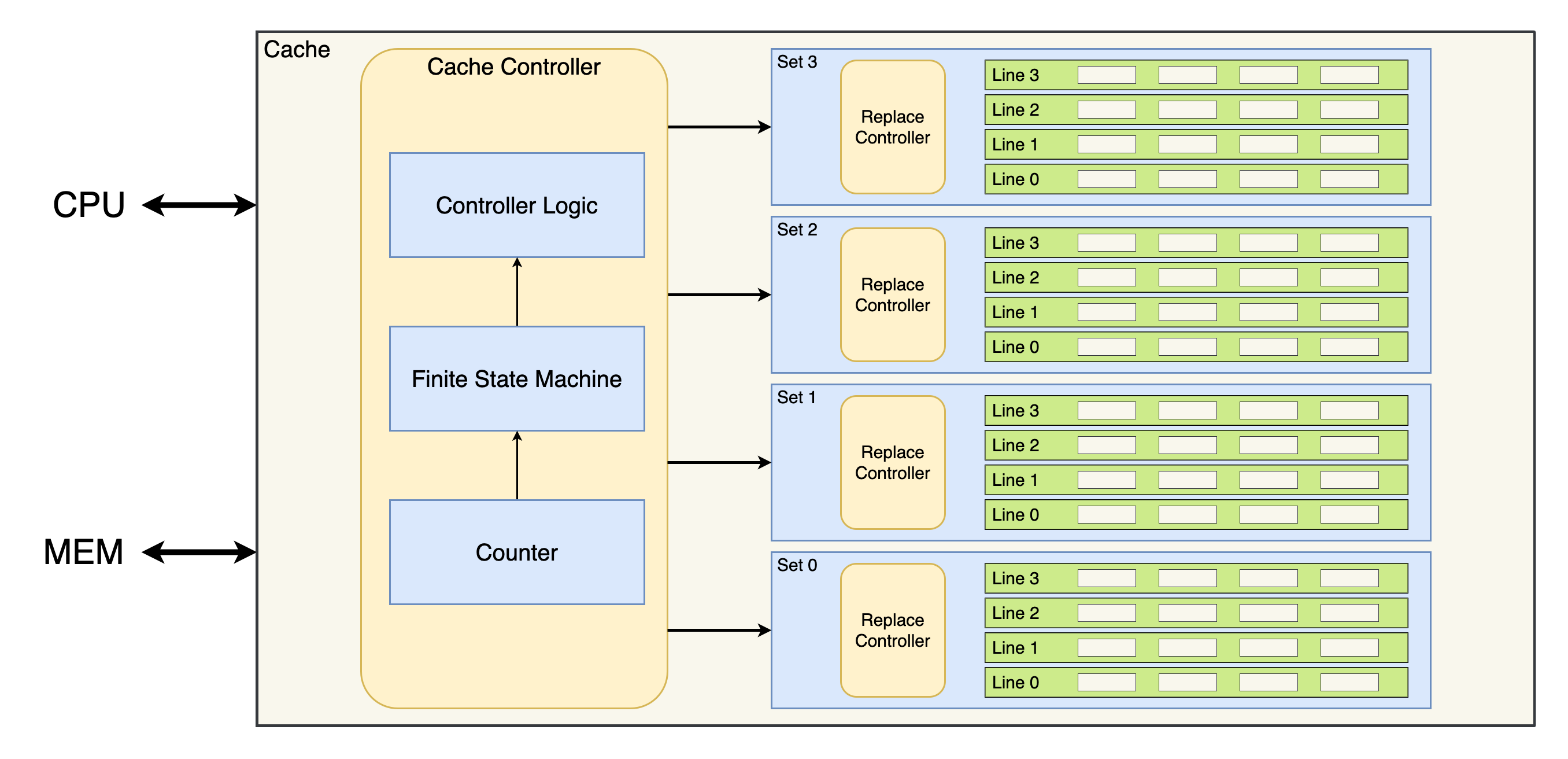
2.1 Cache
Cache 负责输入 CPU 传来的地址、信号及数据,交由 Cache Controller 解析得到相应的控制信号,以控制读写 set / 内存的数据,最终将 set 的输出返还给 CPU。
代码见 这里。
2.2 Cache Controller
Cache Controller 通过一个有限状态机(Finite State Machine, FSM)来决定当前所处的状态,随后利用组合逻辑得到 set / 内存的控制信号及读写内存的地址(如果需要)。根据 CPU 输入的地址可以唯一确定需要操作的 set,其余 set 将被屏蔽。具体判断读写及返回哪一个 line 的任务交给每个 set 自行完成。
代码见 这里。
2.2.1 FSM
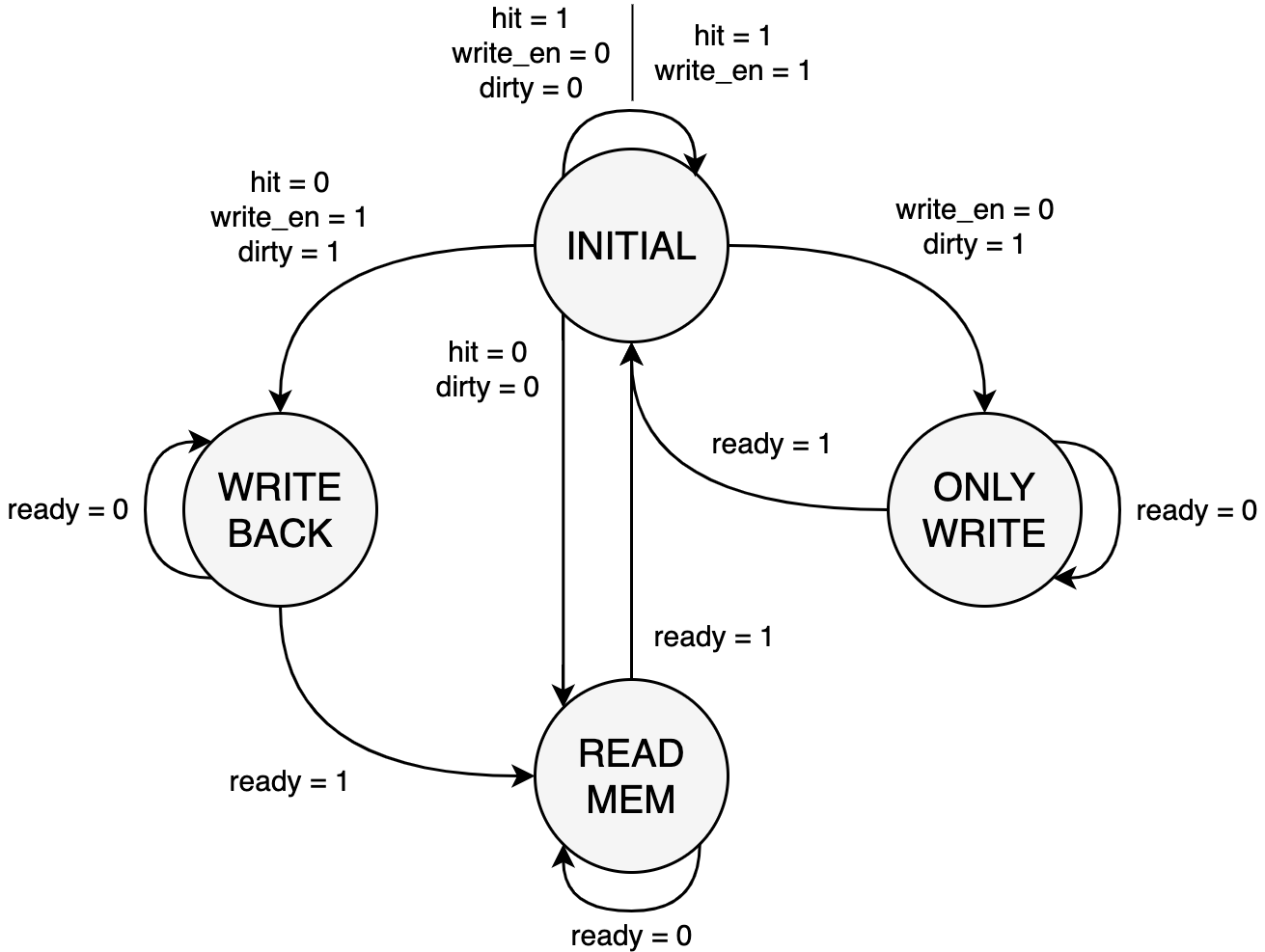
本实现中 FSM 有 4 个状态:INITIAL, WRITE_BACK, ONLY_WRITE, READ_MEM。
INITIAL:初始状态,即 Cache 命中的情况(hit为1)- 如果 Cache 未命中(
hit为0),那么如果当前要操作的 line 是 dirty 的(dirty为1,表示被修改过,但还未写回内存),则切换到WRITE_BACK状态写回新数据,否则(dirty为0)切换到READ_MEM状态从内存读取数据。 - 这里有一个特例,当 CPU 需要读一个 dirty 的 line 时(
write_en为0,dirty为1),无论是否命中,FSM 都将切换到ONLY_WRITE状态将 dirty line 写回内存。
- 如果 Cache 未命中(
WRITE_BACK:写回状态,将 dirty line 写回内存- 阻塞 Cache 到写入完成后(
ready为1)切换到READ_MEM状态,默认需要等待 4 个时钟周期(取决于 line 的大小LINE_SIZE,由参数CACHE_B决定)。 - 计时的工作交给 Counter 完成(计数器从 0 开始计时,需要启用时传入
wait_rst信号刷新),实现中ready信号由wait_rst信号表示,其值为wait_time == WAIT_TIME - 1(布尔值),其中WAIT_TIME即预设的等待时间,默认为LINE_SIZE(参数可在cache_controller.sv中调整,要求值不能低于LINE_SIZE)。
- 阻塞 Cache 到写入完成后(
ONLY_WRITE:只写回状态- 基本同
WRITE_BACK状态,区别是写入完成后直接返回INITIAL状态,而不进入READ_MEM状态。这是因为此时内存和 Cache 的数据是一致的,也不需要替换 line,因此不需要读取内存。本次测试中,引入ONLY_WRITE状态的这项优化将 CPI 降低了约 $2\%$。
- 基本同
READ_MEM:读内存状态,从内存读取数据到 Cache- 阻塞 Cache 到读入完成后(
ready为1)切换到INITIAL状态,默认需要等待 4 个时钟周期。
- 阻塞 Cache 到读入完成后(
2.2.2 Controller 逻辑
根据 FSM 的当前状态,Cache Controller 输出 set / 内存的控制信号,如下所示:
| 信号 | INITIAL | WRITE_BACK | ONLY_WRITE | READ_MEM | Disabled |
|---|---|---|---|---|---|
write_en | write_en & hit | 0 | 0 | 1 | 0 |
update_en | 0 | 1 | 1 | 1 | 0 |
set_valid | write_en & hit | 1 | 1 | wait_rst | 0 |
set_dirty | write_en & hit | 0 | 0 | 0 | 0 |
strategy_en | 1 | 0 | 0 | 1 | 0 |
offset_sel | 1 | 0 | 0 | 0 | 0 |
mem_write_en | 0 | 1 | 1 | 0 | 0 |
其中各控制信号的含义如下:
write_en:是否对 line 进行写操作,同时将当前 line 设置为 dirty。update_en:是否对 line 的状态进行更新,即分别更新valid和dirty位为set_valid和set_dirty,其中对dirty位的更新将覆盖write_en的操作。set_valid:是否将当前 line 设置为 valid。此后如果此 line 的 tag 和访问地址的 tag 字段匹配,就会返回 Cache 命中。set_dirty:是否将当前 line 设置为 dirty。strategy_en:是否启用 Replace Controller,用于决定替换掉哪一个 line。如果未启用则 Replace Controller 保持之前的输出。offset_sel:此值为1时,Cache 与 CPU 交互,访问 line 的 block offset 由 CPU 输入的地址提供,写入 line 的数据(如果需要)为 CPU 输入的数据。此值为0时,Cache 与内存交互,访问 line 的 block offset 由当前访问的内存地址提供,写入 line 的数据为从内存读取的数据。mem_write_en:是否对内存进行写操作。
2.3 Set
得到控制信号的 set 需要判断读写及返回哪一个 line 的数据。本实现中,每个 line 自行检查 tag 是否匹配,并返回是否命中,命中的 line 将同时返回对应 block 的数据。如果存在命中的 line,set 就返回这个 line 的数据,否则由 Replace Controller 决定接下来应该写入(覆盖)哪一个 line。
代码见 这里。
2.4 Replace Controller
Replace Controller 根据当前每个 line 的 valid 和 hit 情况决定接下来应该替换的 line。当 strategy_en 为 1 时启用,否则保持之前的输出。
根据参数 REPLACE_MODE,Replace Controller 决定当前采用的缓存替换策略。若 Cache 未命中,先检查是否有 line 不是 valid 的,如果有则替换其中一个,否则根据如下策略进行替换:
- LRU:维护一个大小为
SET_SIZE的数组 $T$,其中SET_SIZE为每个 set 的 line 数,初值为全 $0$。每当 Cache 命中时,命中 line 的索引 $i$ 对应的 $T_i$ 置 $0$,其余索引 $j$ 对应的 $T_j$ 加 $1$。若 Cache 未命中(且所有 line 均为 valid),则替换索引 $i$ 对应的 $T_i$ 最大的 line。 - RR:若 Cache 未命中,则随机替换一个 line,利用了 SystemVerilog 的系统函数
$urandom。 - LFU:维护一个大小为
SET_SIZE的数组 $F$,初值为全 $0$。每当 Cache 命中时,命中 line 的索引 $i$ 对应的 $F_i$ 加 $1$。若 Cache 未命中,则替换索引 $i$ 对应的 $F_i$ 最小的 line。
这里我们将替换策略单独放在了一个模块中,因此想补充其他策略也很容易。
代码见 这里。
3 一些改动
本 Cache 的实现基于 之前 实现的流水线 MIPS CPU,这里注明所做的一些改动。
由于 Cache 未命中时需要读写内存,在此期间 CPU 不能访问 Cache,否则会发生数据冲突,此时需要 stall 整个流水线1。本实现中,icache 的 stall 信号为 istall,dcache 的 stall 信号为 dstall,用于使 icache 和 dcache 同时至多有其一访问内存,而 CPU 只有在两者都没有 stall 时才能继续运行。为防止两者互锁,此处对这两个信号进行了互斥处理。
assign istall = ~dstall & dcen & ~dhit;
assign dstall = ~istall & ~ihit;其中,ihit 和 dhit 分别表示 icache 和 dcache 命中,dcen 表示 CPU 需要读写内存。因此这里对 mips 的端口进行了一些修改,新增了输入端口 ihit, dhit 和输出端口 dcen。
assign dcen = memwrite | mem_to_reg_m;
// assign stall_cache = ~ihit | (dcen & ~dhit);
本来 ihit, dhit, dcen 还要用于决定是否 stall 流水线,但这里直接通过屏蔽 CPU 时钟实现了,就无需再改动 mips 的代码。
在原测试程序中,icache 和 dcache 共用一个 stall 信号,这将导致 CPU 直接卡死。因此这里修改了测试程序的代码,使用了以上实现方式(即 icache 和 dcache 分别使用独立的 stall 信号)。
此外,由于新增的 random write 样例需要访问 128 位 dmem,因此也将 dmem 的内存大小进行了相应调整。
4 样例测试
4.1 测试结果



4.2 测试环境
- Windows 10 Version 2004 (OS Build 19041.264)
- Vivado v2019.1
4.3 测试分析
这里 CPI 相较原流水线 MIPS CPU 有所升高是正常现象,因为 Cache 引入了 4 个时钟周期的 miss penalty,更加符合实际情况2。在不同参数下进行测试,各替换策略的 CPI 如下所示:
| 替换策略 | CPI #1 | CPI #2 | CPI #3 |
|---|---|---|---|
| LRU | 1.997842 | 1.997646 | 2.004709 |
| RR | 1.990779 | 1.995880 | 2.004709 |
| LFU | 2.015499 | 2.017069 | 2.004709 |
- $(t,s,b,e)=(26,2,4,4)$:256 bytes 4 路组相联映射(默认)
- $(t,s,b,e)=(25,3,4,2)$:256 bytes 2 路组相联映射
- $(t,s,b,e)=(24,4,4,1)$:256 bytes 直接映射
可见在缓存大小不变的情况下,缓存效果大体上呈现 RR ≈ LRU > LFU 的趋势(采用直接映射时替换策略无意义,因此忽略),而路数的影响似乎并不大。当然这也与测试样例的设计有关,这里样例本身也比较少,只能做一个粗略的估计。
如果将缓存扩大一倍,同时相应地将路数也增加一倍呢?
| 替换策略 | CPI #1 | CPI #2 | CPI #3 | CPI #4 |
|---|---|---|---|---|
| LRU | 1.799882 | 1.797920 | 1.797920 | 1.797920 |
| RR | 1.799882 | 1.797920 | 1.797920 | 1.797920 |
| LFU | 1.799882 | 1.797920 | 1.797920 | 1.797920 |
- $(t,s,b,e)=(26,2,4,8)$:512 bytes 8 路组相联映射
- $(t,s,b,e)=(25,3,4,4)$:512 bytes 4 路组相联映射
- $(t,s,b,e)=(24,4,4,2)$:512 bytes 2 路组相联映射
- $(t,s,b,e)=(23,5,4,1)$:512 bytes 直接映射
好吧,缓存太大了,当前测试样例体现不出差距。不过至少说明扩大缓存对于缓存效果的提升还是很明显的,毕竟需要替换缓存的次数减少了。
如果将缓存缩小一半,同时相应地将路数也减少一半呢?
| 替换策略 | CPI #1 | CPI #2 |
|---|---|---|
| LRU | 2.128311 | 2.112811 |
| RR | 2.108495 | 2.112811 |
| LFU | 2.113008 | 2.112811 |
- $(t,s,b,e)=(26,2,4,2)$:128 bytes 2 路组相联映射
- $(t,s,b,e)=(25,3,4,1)$:128 bytes 直接映射
顺位又变成 RR ≈ LFU > LRU 了。可能是因为 LRU 本身对长循环不太友好,因为此时最近访问过的数据反而不容易再被访问。于是当缓存太小时,这个问题就暴露了出来。
总的来说,RR 策略容易实现,且效果稳定良好,反而是一个不错的选择,比较意料之外。
参考资料
- David A. Patterson, John L. Hennessy: Computer Organization and Design Fifth Edition
- Randal E. Bryant, David R. O’Hallaron: Computer Systems: A Programmer’s Perspective Third Edition
- Cache replacement policies - Wikipedia