
计组 - Lab 4: 分支预测
动态分支预测器,实现了一个 2 位 Tournament Predictor,其中包含一个 Global Predictor、一个 Local Predictor 和一个 Static Predictor,使用 SystemVerilog 编写。
Introduction to Computer Systems II (H) @ Fudan University, spring 2020.
1 参数
本分支预测器在实现中默认使用 Tournament Predictor,当 miss 时优先选择 Global Predictor。当 Global Predictor 和 Local Predictor miss 时使用 Static Predictor 作为 fallback,Static Predictor 默认采用 BTFNT(Backward Taken, Forward Not Taken)跳转策略。
在 bpb.svh 中可调整以下参数:
BPB_E:BHT(Branch History Table)地址的位数 $e$,对应 BHT 的大小为 $2^e$ 条记录,默认为 $10$BPB_T:地址中用作 BHT 和 PHT(Pattern History Table)索引的位数 $t$(忽略最低 2 位的低 $t$ 位),默认为 $10$- 本实现使用了直接映射,因此 $t=e$,否则需要使用其他映射方式,可以是类似于 Cache 的组相联映射,也可以通过某种 hash 函数来映射。
MODE:当前预测模式 $\mathrm{mode}$,可修改为以下值,默认为USE_BOTHUSE_STATIC:使用 Static Predictor,对应 $\mathrm{mode}=0$USE_GLOBAL:使用 Global Predictor,对应 $\mathrm{mode}=1$USE_LOCAL:使用 Local Predictor,对应 $\mathrm{mode}=2$USE_BOTH:使用 Tournament Predictor,对应 $\mathrm{mode}=3$
PHT_FALLBACK_MODE:当 Tournament Predictor miss 时优先选择的预测模式,可修改为USE_GLOBAL或USE_LOCAL,默认为USE_GLOBAL
在 static_predictor.svh 中可调整以下参数:
FALLBACK_MODE:Static Predictor 采用的跳转策略 $\mathrm{mode}$,可修改为以下值,默认为BTFNTNOT_TAKEN:总是不跳转,对应 $\mathrm{mode}=0$TAKEN:总是跳转,对应 $\mathrm{mode}=1$BTFNT:向后分支(往较低地址)跳转,向前分支(往较高地址)不跳转,对应 $\mathrm{mode}=2$
2 结构
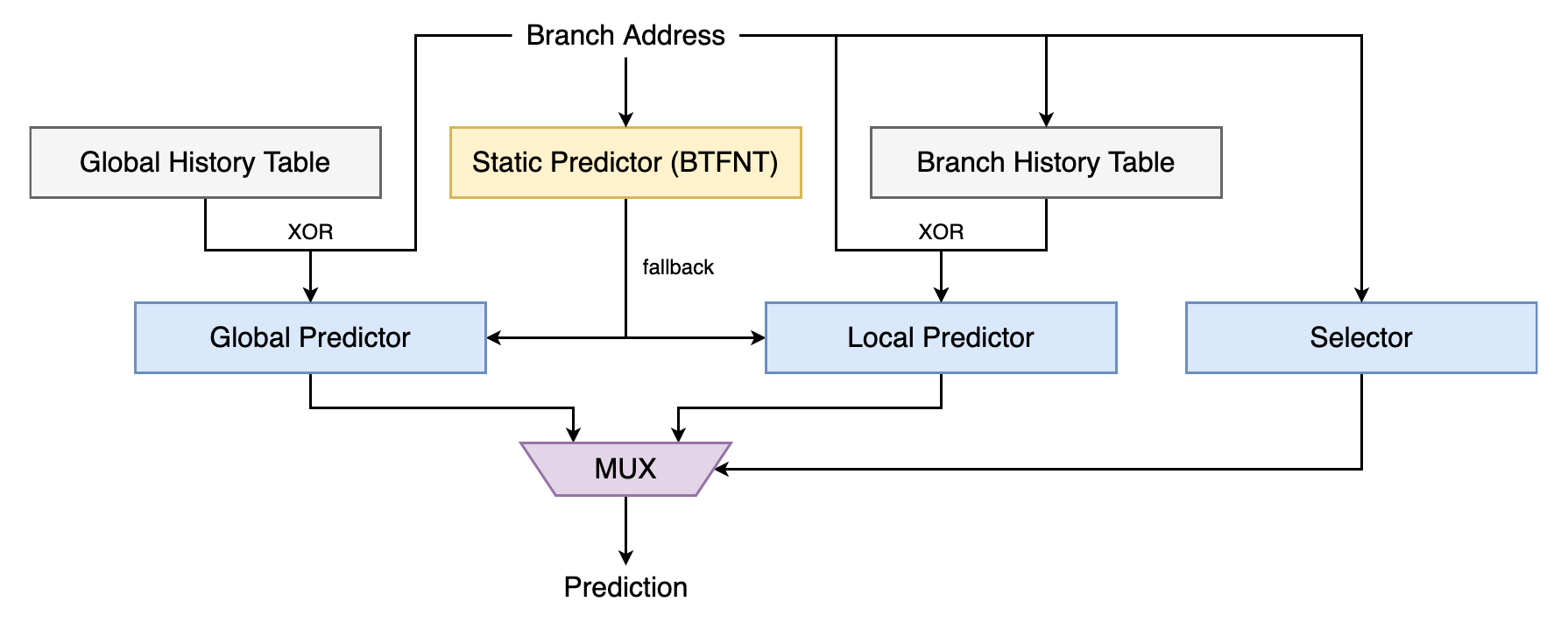
2.1 Global History Table
GHT(Global History Table)是一个全局分支跳转记录表,所有分支的跳转记录共享一个位移寄存器。Global Predictor 利用 GHT 提供的最近一次分支跳转记录 ght_state 进行预测。
Global Predictor 的优势在于能够发现不同跳转指令间的相关性,并根据这种相关性作预测;缺点在于如果跳转指令实际上不相关,则容易被这些不相关的跳转情况所稀释(dilute)。
代码见 这里。
2.2 Branch History Table
BHT(Branch History Table)是一个局部分支跳转记录表,每个条件跳转指令的跳转记录都分别保存在按地址直接映射的专用位移寄存器里。Local Predictor 利用 BHT 提供的指定分支最近一次跳转记录 bht_state 进行预测。
由于映射时使用了地址的低 $t$ 位 index 作为索引,存在重名冲突(alias)的可能,但并不需要处理。因为毕竟只是「预测」,小概率发生的重名冲突所导致的预测错误并不会有很大影响。
Local Predictor 的优势在于能够发现同一跳转指令在一个时间段内的相关性,并根据这种相关性作预测;缺点在于无法发现不同跳转指令间的相关性。
代码见 这里。
2.3 Pattern History Table
Global Predictor, Local Predictor 和 Selector 都分别是一个 PHT(Pattern History Table)。其中 Global Predictor 使用 index ^ ght_state 索引,Local Predictor 使用 index ^ bht_state 索引,Selector 使用 index 索引。使用 $\mathrm{XOR}$ 运算来 hash 是为了在 PHT 的大小较小时,通过将索引地址随机化,降低重名冲突发生的概率,同时尽可能减少因此增加的延迟。
Selector 根据上次预测的情况决定本次选用 Global Predictor 还是 Local Predictor 进行预测。作为 PHT,与 Global Predictor 和 Local Predictor 一样,需要 2 次错误预测才会使得 Selector 切换预测模式,原理见 2.4 节。整个机制综合起来,就是所谓的 Tournament Predictor。
Tournament Predictor 的优势在于能够根据不同分支的不同情况,选择最适合其特征的预测模式。因此在大多数情况下,Tournament Predictor 会有相对较好的表现。
代码见 这里。
2.4 Saturating Counter
对于每一个保存的记录,其形式是一个 2 位饱和计数器(Saturating Counter),即一个有 4 种状态的状态机。

00:Strongly not taken01:Weakly not taken10:Weakly taken11:Strongly taken
也就是说,通常需要连续 2 次实际跳转 / 不跳转,一种状态才会翻转到另一种状态,从而改变预测结果。这种机制提高了预测器的稳定性,不会因为一点小波动就立刻改变预测结果。
代码见 这里。
2.5 Static Predictor
在程序刚开始运行时,GHT, BHT, PHT 都还是空的,此时需要 fallback 到 Static Predictor。Static Predictor 默认采用 BTFNT 策略,相较于其他静态预测模式,能够较好地同时处理循环1和一般跳转情况。
代码见 这里。
2.6 Branch Prediction Buffer
BPB(Branch Prediction Buffer)是这个动态分支预测器的主体,负责预测跳转地址并与 CPU 交互。
实现中,BPB 先获得 Fetch 阶段的指令及其地址,通过 Parser 进行解析,得到一些在 Fetch 阶段就能知道的信息(如指令类型、跳转目标地址等)。目前能够很好地处理 j, jal, beq, bne 指令,但无法处理 jr 指令,因为 jr 需要读取寄存器。为了方便起见,还是把 jr 指令留给 Decode 阶段,否则需要处理新的数据冲突和控制冲突。还有一种思路是先预读寄存器里的数据(可能有错误),等到 Decode 阶段发现寄存器里的数据有误时直接 flush 流水线,这样可以不用处理冲突,同时很多情况下可以减少 jr 指令的 CPI。由于时间原因,这里并没有尝试实现。
通过 Fetch 阶段得到的信息,利用 Tournament Predictor 进行预测,并将预测跳转的目的地址返还给 CPU。随后在 Decode 阶段检查预测结果是否正确,如果不正确,则将 miss 信号置 1,并传给 CPU 和各 PHT。CPU 接收到 miss 信号后,Fetch 阶段重新计算正确的地址(此时正确的 PC 地址在 Decode 阶段,需要回传给 Fetch 阶段),Hazard Unit 发出控制信号 flush 流水线寄存器 decode_reg 和 execute_reg。各 PHT 接收到 miss 信号后,根据实际的 taken 情况进行更新。
代码见 这里。
3 一些改动
本动态分支预测器的实现基于 之前 实现的带 Cache 的流水线 MIPS CPU,这里注明所做的一些改动。
首先在 mips 里新增了 BPB 模块,并且新增了其与 Fetch 阶段和 Hazard Unit 间的交互逻辑。Fetch 阶段更改了 pc_next(新的 PC 值)的选择逻辑,当预测失败或当前指令为 jr 时选择原本的 pc_next 值,否则选择 BPB 的预测值 predict_pc。这里 BPB 也可以预测非跳转指令的 pc_next 值(总是 pc + 4),因此就将这部分逻辑合并进 BPB 了。
此外,根据 2.6 节的描述,修改了 hazard_unit 的 flush_d 信号。由于现在采用动态分支预测,跳转指令在 Fetch 阶段后就会直接跳转,而不像原来需要再读取一条无用指令,因此不需要针对跳转指令进行额外的 flush 操作(jr 指令除外)。实际上这个 penalty 是转移到了预测失败的情况,但现在预测成功时就没有这个 penalty 了,动态分支预测主要就是优化了这个地方。
assign flush_e_o = stall_d_o || predict_miss_i;
assign flush_d_o = predict_miss_i || jump_d_i[1]; // wrong prediction or JR
4 样例测试
4.1 测试结果



4.2 测试环境
- Windows 10 Version 2004 (OS Build 19041.264)
- Vivado v2019.1
4.3 测试分析
同等条件下,未使用动态分支预测时 CPI 为 1.997842。可见,动态分支预测将 CPI 降低了 $10\%$ 左右,这个优化效果还是比较可观的。以下调整不同参数,进行了一些测试。
Tournament Predictor miss 时优先选择哪种预测模式?
| 预测模式 | CPI |
|---|---|
| Local | 1.794349 |
| Global | 1.794741 |
似乎 Local Predictor 在冷启动阶段的短时间内表现稍好一点。
BPB 默认使用哪种预测模式?
| 预测模式 | CPI |
|---|---|
| Both | 1.794741 |
| Local | 1.794937 |
| Global | 1.794152 |
| Static | 1.849294 |
| None | 1.997842 |
可见动态分支预测显著优于静态分支预测。但为什么 Tournament Predictor 的表现没有只使用 Global Predictor 时好呢?可能原因是测试样例整体都偏向于 Global Predictor 的优势区,而 Tournament Predictor 在冷启动阶段需要调整预测模式的选择,这需要一定的时间,在这段时间里其表现就不如 Global Predictor。如果个别测试样例对 Local Predictor 或 Global Predictor 有明显偏好,但整体而言没有呈现明显偏向性,这种情况下 Tournament Predictor 可能会有较好的发挥。
Static Predictor 采用哪种策略?
| 预测策略 | CPI |
|---|---|
| Not Taken | 1.990190 |
| Taken | 1.793962 |
| BTFNT | 1.849294 |
对于静态分支预测,预测效果 Taken > BTFNT > Not Taken,比较意外。通常来说应该是 BTFNT 的效果较好,可能比较依赖于测试样例的具体构造。
参考资料
- David A. Patterson, John L. Hennessy: Computer Architecture: A Quantitative Approach Sixth Edition
- 18-740/640 Computer Architecture Lecture 5: Advanced Branch Prediction - CMU
- Branch predictor - Wikipedia
这里利用的是循环在绝大多数时候(除了最后一次)总是向后跳转的特性。 ↩︎